AES ECB Chosen Plaintext Attack
This week I have a different post than my usual pwn writeups. Recently, I started studying cryptography in
I always found cryptography fascinating, encrypting data such that no one can decrypt it. Looking at how many rounds of XORs AES does, one simply thinks “There is no way you can reverse that!”. It is true, you can’t actually reverse a given cipher text and figure out the AES key, it is pretty safe. But there is a catch, depending on how it is used and if we can encrypt arbitrary data, we can decrypt a given cipher text without knowing the key! Let’s dive into how this can be done for AES ECB mode.
AES ECB mode
What is the ECB mode? ECB mode - electronic codebook - is the simplest form of AES. Data is divided into fixed sized blocks and each block can be encrypted/decrypted individually without any reference to future or past blocks. What this means is if a same block is given same encrypted block is generated after encryption:
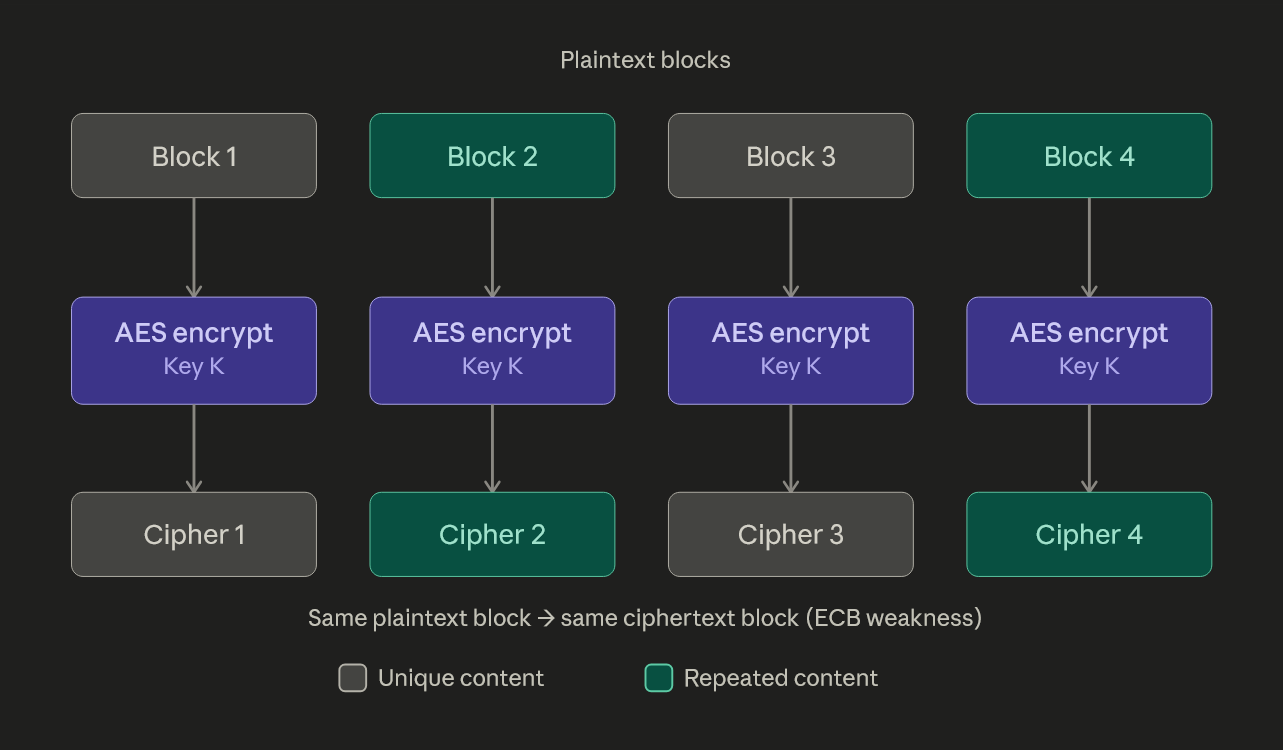
I am sure if you are reading this, you must have seen the encrypted penguin image:
 Source: wikipedia
Source: wikipedia
AES itself is unbreakable, but here we have a weakness, a very big weakness that AES-ECB is no longer accepted. Even though the encryption itself is immune to attacks, how the encryption is implemented over large blobs of data is the problem here. It generated predictable patterns since it creates the same encryption for the same given input block. This is a pretty well known fact but how do we exploit this really? Let’s have a look.
Test Scenario
Pwn college is a great resource, and I don’t want to ruin your experience by sharing my solutions to their crypto challenges. So instead, I decided to create a test case that I can go over without spoiling the solutions to pwn college crypto challenges. I got some help from claude to design this case:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import string
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
from Crypto.Random import get_random_bytes
BLOCK_SIZE = 16
# --- The "server side": a secret key and a hidden value the attacker wants ---
SECRET_KEY = get_random_bytes(16)
SECRET_FLAG = b"flag{ecb_leaks_secrets_byte_by_byte}"
def oracle(attacker_input: bytes) -> bytes:
"""
Simulates a vulnerable encryption endpoint.
It always appends the secret after whatever the attacker supplies,
then encrypts everything with AES-ECB.
"""
cipher = AES.new(SECRET_KEY, AES.MODE_ECB)
plaintext = pad(attacker_input + SECRET_FLAG, BLOCK_SIZE)
return cipher.encrypt(plaintext)
Here we are encrypting a secret flag and the user is given an encrpytion oracle that will encrypt any given data by ‘prepending’ user data to the secret text. Attacker wants to discover this secret text, and have only access to this encryption oracle. I know we can plainly see the secret text in the code, ignore that and assume it is not known for the simplicity of this test case scenario. Attack condition in this instance is that user input is prepended to the secret text before encryption. User has the control over input size that will get encrypted.
Attack
Okay we have an encryption oracle that will encrypt the data we provide to it along with the secret text. What can we actually do with this?
- Discover that it is using ECB mode
- Discover block size
- Discover the length of secret text appended to the user input
- Discover secret text by chosen plaintext attack
ECB Mode Confirming and Discovering Block Size
Since the user can provide any length input it is pretty easy to confirm if it is using ECB mode or not. Providing a sufficiently long and same repeating bytes would create same repeating input blocks that would generate same cipher blocks if it is using ECB mode
1
2
3
4
5
6
7
8
9
10
11
test_bytes = b'A' * 64
print(oracle(test_bytes).hex())
# RESULTING BYTES separated by the repetition:
#
# cfa012639aaf0d2a84c3841ee8fd70f2
# cfa012639aaf0d2a84c3841ee8fd70f2
# cfa012639aaf0d2a84c3841ee8fd70f2
# cfa012639aaf0d2a84c3841ee8fd70f2
# f2a9b1982f62dc440f72048ba481d0c95f601391c17fb8c171421c54a9e9f6435eaf19a5d1b7b43d75e009e7ff3331d7
Looking at the encrypted blocks we can clearly see repeating encrypted blocks; without a doubt that is ECB mode.We can also see that repeating blocks are 32 hex = 16 bytes long. This also confirms that the block size is 16 bytes.
Discover Secret Text Length
Discovering secret text length is technically not required to perform the CPA. But I ended up doing it while trying to solve challenges, so why not document here for my future self, right?
It is quite simple, we rely on the fact that ECB mode is a block encryption. If input size isn’t divisible by the block size: input is padded. There is no work around to this, without an actual block size input ECB can’t encrypt. For padding PKCS #7 is used widely.
PKCS #7 Padding
It is quite a simple and straightforward approach that helps us discover how many bytes are padded. Zero padding is quite simple but when data is padded with zeros, there is no direct way to say how many bytes of zeros are part of data and how many bytes are padding bytes. To eliminate this problem, PKCS7 padding uses how many bytes to pad as the padding byte:
- Calculate how many bytes needed to be padded
pad_size = input_len % block_size - If not zero, input is padded with
pad_sizenumber of bytes where each byte equals to pad_size - If zero, input is padded with an extra block where each byte equals to block_size
Additional block creation when we have input size divisible by the block size is the point we use to figure out secret text length. Provide 0 to n bytes as input and observe the output size, when output size increases with an extra block -> that is the point we reached total input size that is divisible by block size. And then we can simply find the secret text length by using that size and how many bytes we added.
CPA - Chosen Plaintext Attack
Let’s come to the core point of this post: CPA. Nature of CPA comes from the fact that user can provide a chosen plaintext. Since we know the block size, why don’t we provide block_size - 1 known input, how would blocks look like, let’s say block size is 4 simplifying the example:
UUUS SSSS SSSS SSSS SS22
Here user provided 3 bytes which then gets appended with secret text, and finally since total input length is not divisible by block size, so it needs to be padded 2 bytes. I padded with 2 to demonstrate PKCS #7 padding. That final padding doesn’t really matter, what matters is once this is encrypted we will get 5 blocks from AES ECB:
C1 C2 C3 C4 C5
where C1 is the encrypted block of plaing text UUUS. Well we provided U, so we know the first three bytes of this plaintext, but we don’t know the final byte. Now we got this cipher text, this cipher text is unique such that only UUUS will generate this cipher text. Now we can try all possible bytes for the unknown S byte, only 256 options and we can discover that byte:
1
2
3
4
5
6
7
8
UUU0 SSSS SSSS SSSS SS22
UUU1 SSSS SSSS SSSS SS22
UUU2 SSSS SSSS SSSS SS22
UUU3 SSSS SSSS SSSS SS22
UUU4 SSSS SSSS SSSS SS22
UUU5 SSSS SSSS SSSS SS22
...
UUU256 SSSS SSSS SSSS SS22
It is a simple brute force with 256 encryptions max. One of the first encrypted blocks will match the encrypted block of UUUS and that will give us the unknown byte S! What about the rest of bytes? It is similar, let’s annotate the decrypted/discovered bytes with D, since we now know the first byte we can prepend with block_size - 2 bytes:
UUDS SSSS SSSS SSSS S333
Since we are prepending 2 bytes, instead of 3, we now have 2 bytes from secret text inside the first block which we already know the first one. Once this is encrypted, we will know the cipher text of block UUDS. With the same brute force logic we can try all possible bytes for the unknown 4th byte:
1
2
3
4
5
UUD0 SSSS SSSS SSSS S333
UUD1 SSSS SSSS SSSS S333
UUD2 SSSS SSSS SSSS S333
...
UUD256 SSSS SSSS SSSS S333
And again only one of the cipher texts of first block will match the cipher text of block UUDS. That matching byte will give us the second unknown S byte. I hope you can see the picture now. Each iteration will give us a byte and each iteration at max requires 256 encryptions. It is possible to reduce each iteration’s steps by reducing search steps from 256 bytes to alphabet or printable characters if such expectation can be made.
Now, let’s think about what will happen when we discover one full block of secret text, we keep doing the same logic but this time our reference block for comparison will change. Now, let’s say we reached 4 bytes discovered and sent 3 bytes padding again:
UUUS SSSS SSSS SSSS SSSS SS22
Since we discovered 4 bytes, we already know the first 4 S, 5th one is unknown. But this gives us a second block where we know all the bytes other than final byte. Now for brute forcing we provide 3 bytes padding along with 4 discovered bytes and brute forced byte:
1
2
3
4
UUUD DDD0 SSS....
UUUD DDD1 SSS....
...
Again same logic, second block’s cipher text will match the target cipher text. This logic keeps repeating until we discover all the secret text bytes. Here how it looks in the code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
def decrypt_secret(block_size: int, alphabet: str = None) -> bytes:
if alphabet is None:
alphabet = string.printable
secret_len = len(oracle(b"")) - len(pad(b"", block_size)) # rough upper bound, refined as we go
decrypted = b""
# We just keep decrypting bytes until we hit padding / can't find a match.
max_len = len(oracle(b"")) + block_size
for i in range(max_len):
pad_len = block_size - 1 - (i % block_size)
padding = b"A" * pad_len
# Here we select the target block to extract cipher text
# More bytes we discover, more further we will be targeting
block_index = i // block_size
target = oracle(padding)[block_index * block_size:(block_index + 1) * block_size]
found = None
for ch in alphabet.encode():
guess = padding + decrypted + bytes([ch])
test_block = oracle(guess)[block_index * block_size:(block_index + 1) * block_size]
if test_block == target:
found = bytes([ch])
break
if found is None:
# No matching byte means we've run past the real secret (hit padding bytes).
break
decrypted += found
return decrypted
recovered = decrypt_secret(block_size)
Core logic is as explained above. Pad bytes to get secret text positioned accordingly in right block to generate target cipher text, and then send padding + discovered + brute force byte to search for a matching cipher text.
Final Notes
Honestly first time I saw how this worked I was shocked. I didn’t know much crypto back then, I was assuming AES was a very strong encryption that couldn’t be brute forced for billions of years. Well that is still true, but what I didn’t know was AES modes was a thing and how it is used could cause such weaknesses.
If you want to experience this on first hand with practical examples, go and check out pwn college. They got step by step challenges that move you towards a full solution. This was only one mode of AES, more stuff to come! As always, keep learning!