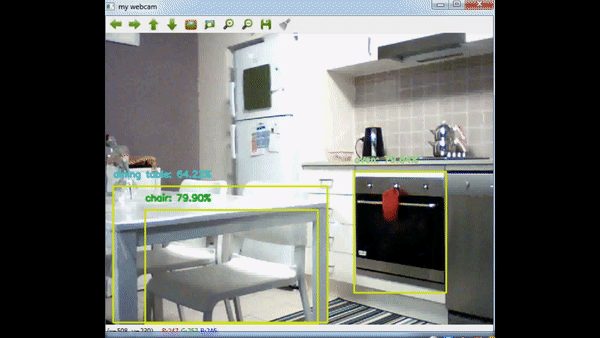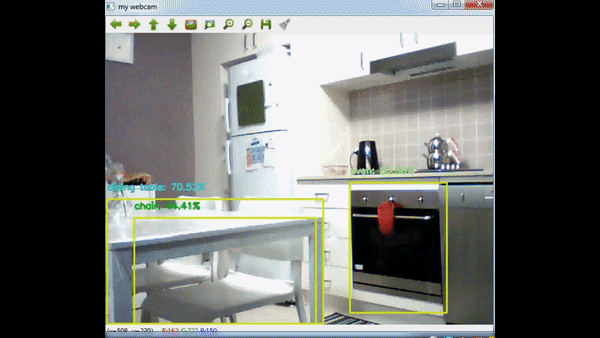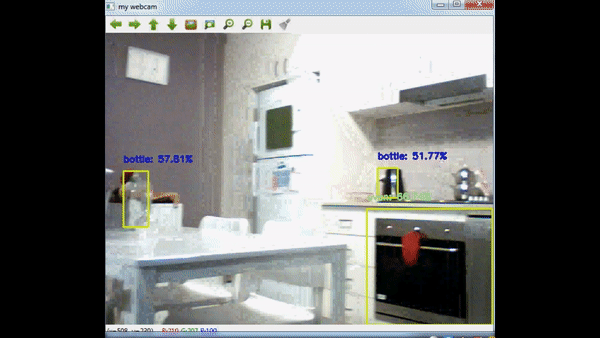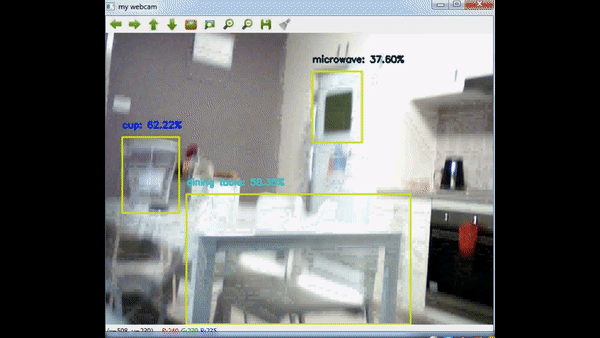
Node Js Backend – Raspberry Pi 2 32bit Problem
Recently, I have started working on a side project for a non-profit organisation. They needed a volunteer management app for handling help requests and notification of the deliveries to volunteers. After some initial research and some discussions with the project manager ChatGPT, I came up with this awesome todo list:
- Create backend server and API using Node js
- Write an app using Flutter with Dart.
I know it is a very comprehensive list 😂Let me be clear, my only exposure to the web development was more than 10 years ago and it was just one uni course on php development. So I didn’t have a clear idea on how the steps would shape up. Now that is out of the way, I needed to learn and quickly develop the first prototype. You can see my awesome, beautiful mess of a spaghetti code here: https://github.com/yusuftas/team_volunteer
(more…)