Using Tensorflow Object Detection API with OpenCV
In this post, I will go over how to use Tensorflow Object Detection API within OpenCV. To be honest, I haven’t used OpenCV for quite some time. And after recently looking into it, I have realized how awesome OpenCV has become. It now has a dedicated DNN (deep neural network) module. This module also has functionality to load Caffe and Tensorflow trained networks. I am just so happy to see that functionality in OpenCV. Just think about it, you can use your Caffe or Tensorflow trained networks within OpenCV.
Alright, enough blubbering, let’s get back to the topic. In this post, I will use OpenCV DNN’s functionality to load a trained tensorflow network and use this network to apply object detection to a webcam stream. So in the end, we will have a display that shows webcam stream and in the stream we modify the frames and display detected objects with rectangles. Before we begin, let’s start with the result:
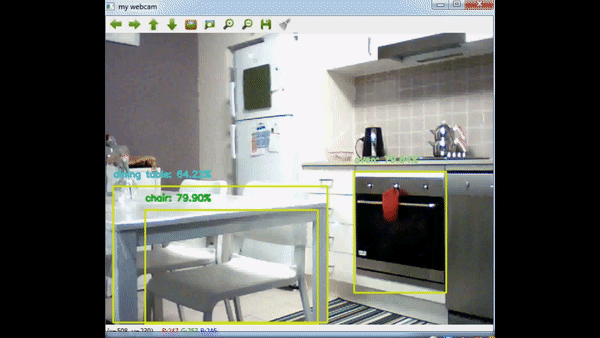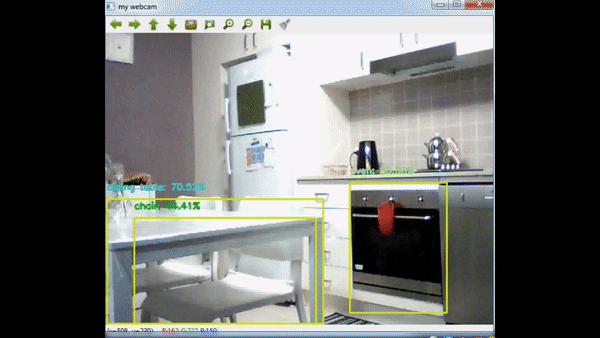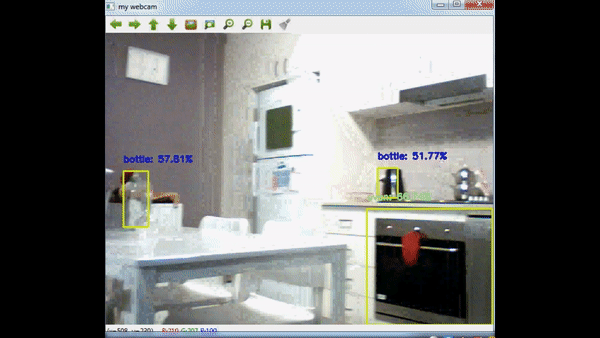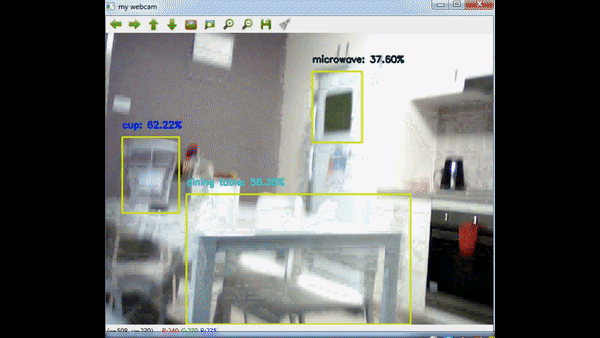
Firstly, let’s look into the network. Technically there are many networks you can use, for this post, I’ve decided to use Mobilenet. You can read their paper from this link: https://arxiv.org/abs/1704.04861. In summary, authors try to decrease network capacity to decrease processing time while also trying to maintain accuracy. That approach makes it even possible to use this network in mobile phones. Try using VGG16 network in a device with limited power and memory :) I won’t go into details of the network structure, if you would like to learn the details, I would highly suggest you to read the paper.
Before we start coding, I need to mention that everything in this tutorial can be done with using only Tensorflow Object Detection API. But what OpenCV does is to take an image processing algorithm and make it so easy to use. So in this tutorial I’m using OpenCV’s DNN module to take care of everything; load the network, do a forward pass with frames and get bounding box predictions etc. You don’t even need to import tensorflow for this tutorial.
Alright, first thing is to get camera stream and display it. Later on, we will expand this code to apply object detection to each frame instead of just displaying. Displaying the camera stream is pretty straightforward in OpenCV:
1
2
3
4
5
6
7
8
9
10
11
12
cam = cv.VideoCapture(0)
while True:
ret_val, img = cam.read() #read the frame from webcam
cv.imshow('my webcam', img)
if cv.waitKey(1) == 27: # 27 is the character code for ESC
break # esc to quit
cam.release() # stop webcam stream
cv.destroyAllWindows()
Now, we got the webcam stream working, next step is to integrate this with object detection. For object detection, I will use Mobilenet as mentioned above. You can find Mobilenet and also inceptionv2 model from Opencv’s documentation. You can also try Inceptionv2 model, but if you don’t have a good GPU, webcam stream will be laggy since the processing time of one frame will limit the FPS. I highly recommend using Mobilenet, if you don’t have a high-end PC.
Now let’s look into object detection part :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
cam = cv.VideoCapture(0)
#pb = './inceptionv2.pb'
#pbt = './inceptionv2.pbtxt'
pb = './mobilenet.pb'
pbt = './mobilenet.pbtxt'
cvNet = cv.dnn.readNetFromTensorflow(pb,pbt) # read the network
while True:
ret_val, img = cam.read()
rows = img.shape[0]
cols = img.shape[1]
cvNet.setInput(cv.dnn.blobFromImage(img, 1.0/127.5, (300, 300), (127.5, 127.5, 127.5), swapRB=True, crop=False))
cvOut = cvNet.forward()
for detection in cvOut[0,0,:,:]:
score = float(detection[2])
if score > 0.3:
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
cv.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (23, 230, 210), thickness=2)
idx = int(detection[1]) # prediction class index.
# draw the prediction on the frame
label = "{}: {:.2f}%".format(classes[idx],score * 100)
y = top - 15 if top - 15 > 15 else top + 15
cv.putText(img, label, (int(left), int(y)),cv.FONT_HERSHEY_SIMPLEX, 0.5, colors[idx], 2)
cv.imshow('my webcam', img)
if cv.waitKey(1) == 27:
break # esc to quit
cam.release()
cv.destroyAllWindows()
I extended the first code snippet to apply object detection. There are several important points in this code that I need to mention :
- Line 10. Here we load the trained network file. Opencv converts it from tensorlow format to OpenCV format. It requires two arguments : frozen inference graph and network description file. You can download these files from the OpenCV wiki page. And if you download it from there, you need to extract frozen_inference_graph file from the compressed file.
- Line 17. In this line, we convert the frame to BLOB type and set this as input to the network. Blob is the 4d matrix representation of your data. Depending on the framework, ordering of axes changes but generally it is (batch_size, channels, row, col) or something close. Since we use only one frame as input, in the output blob; batch size will be one. Channels will be 3 and we convert the ordering of channels BGR(opencv style) to RGB (normal style :) ). And row,col will be (300 300). This input size will be dependent on the network you are using.
- Line 17. Again in line 17, we apply preprocessing to the input image. OpenCV just combined many things into one single line :) . In this preprocessing, we subtract the mean values (R,G,B channels respectively) and rescale the input values according to the network’s specifications. This depends on the pretrained network, some networks just do mean subtraction while some will do mean subtraction and scaling as well. Depending on the network you are using, you should follow its preprocessing procedures.
- Line 20. In this line, we are iterating over each detection box. Each detection box will have several values:
- detection[0] : unknown. I couldn’t find what it stands for, let me know if you know it. :)
- detection[1] : Classification index, any value between 0 to class_count.
- detection[2] : Classification probability 0-1. Higher the number, higher probability network believes it belongs to the class detection[1].
- detection[3:7] : Bounding box coordinates
- Line 27 and 34. In line 27 we draw the rectangle of detection. And in line 34, we add a text of the predicted class of the detection. Note that this code snippet doesn’t show the class list in text. For clarity, I didn’t add it here to reduce clutter. If you would like to see the full code, you can find it in my github page.
I think this is all I can add to this post, you can find the full version of the jupyter notebook file my github page. Put a comment down below if you have questions, and as always keep learning.